OCR Still Leaves Businesses Re-Entering Data
Most companies already have digital files. The real challenge is how information moves after that.
The majority of businesses have spent decades building operations around paper.
Boxes of files in storage rooms.
Archives beneath head offices.
Cabinets full of patient records, invoices, engineering drawings, handwritten notes, and operational documents that teams relied on every day.
And for a long time, the first step toward modernization was straightforward:
Scan everything.
That alone created massive improvements.
Information became searchable.
Files became easier to store, retrieve, and share.
Entire rooms of physical records could suddenly live in a digital environment.
But when the digital files are delivered, manual workflows become the new challenge.
opening files manually
reviewing documents one at a time
copying information into systems
re-entering data into spreadsheets
searching through PDFs for specific details
That’s the difference between working with searchable documents and structured data in your workflow, and why the distinction matters much more today than it did even a few years ago.
OCR Was a Major Step Forward
OCR (Optical Character Recognition) changed the way businesses handled information.
Instead of storing static image files, scanned documents could suddenly become searchable and readable by software systems.
That meant:
contracts could be searched instantly
records became easier to retrieve
archives became accessible
information stopped living entirely inside filing cabinets
For many organizations, that was transformational.
And honestly, it still matters.
A properly digitized archive can completely change how a business operates.
But OCR solves visibility more than usability, recognizing text but will not understand operational context.
That’s where many businesses still encounter friction without realizing why.
Searchable Doesn’t Always Mean Usable
This is the part many organizations discover after digitization projects are already complete.
The files are digital.
But people are still doing the same work around them.
Someone still has to:
open the document
find the relevant information
copy the values
organize the data
move it into another system
validate it manually
At scale, those small actions compound quickly.
A few extra minutes across hundreds or thousands of documents becomes operational drag that quietly slows everything down.
And most businesses don’t initially describe it as a document issue.
They describe it as:
delays
admin overload
slow approvals
fragmented workflows
difficulty accessing information
bottlenecks between systems
In reality, the problem often begins much earlier:
how information moves.
Structured Extraction Changes Everything
This is where things start to evolve.
Structured extraction goes beyond recognizing words on a page.
Instead, it identifies key information and organizes it into usable data structures that workflows and systems can actually work with.
That could mean extracting:
invoice totals
dates
addresses
patient information
handwritten form fields
line items
signatures
operational records
And then restructuring that information into:
spreadsheets
ERPs
CRMs
databases
workflow systems
automation pipelines
The document stops being a static file and functions as operational data.
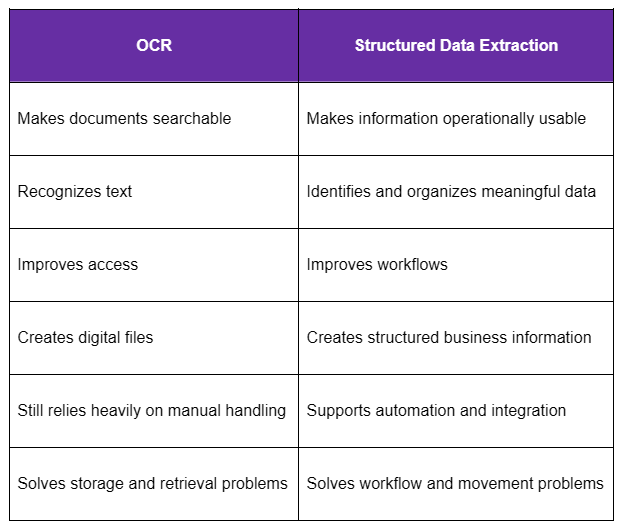
OCR vs Structured Extraction
Both have value in many projects and OCR is still the critical first step. But not the last step.
Businesses trying to reduce manual processes and modernize operations, searchable PDFs are often only the beginning.
The Most Valuable Data in a Business Is Often Already There
One thing we’ve learned over time is that most organizations already possess enormous amounts of valuable operational information.
It’s just trapped inside:
scanned files
paper records
handwritten forms
disconnected archives
static PDFs
decades of documentation
The challenge is really accessibility, structure, and movement.
Once information becomes structured and connected to workflows, businesses usually start seeing improvements almost immediately:
faster retrieval
reduced manual entry
cleaner operations
better visibility
quicker response times
more scalable processes
And importantly, teams spend less time managing information and more time using it.
It’s time to shift to a faster, smarter and easier workflow, powered by artificial intelligence.
That’s an important difference.
Because modern workflows don’t just need files that can be searched.
They need information that can:
move between systems
support automation
reduce repetitive tasks
remain accessible
scale with operations
OCR helped organizations transition away from paper, but structured extraction is helping organizations transition toward connected workflows.
And in many environments, that next step is where the real operational transformation begins.
READ MORE ABOUT DOCUMENT PROCESSING


